Las bases de datos relacionales resuelven la mayoría de problemas. Pero no todos. Un catálogo donde cada producto tiene atributos completamente distintos. Un sistema de caché que necesita responder en microsegundos. Una red social donde las relaciones entre usuarios importan tanto como los usuarios en sí. Hay casos donde otra arquitectura encaja mejor, y para eso existe NoSQL.
¿Qué significa NoSQL?
NoSQL significa literalmente «no solo SQL» (not only SQL). No es un rechazo de las bases de datos relacionales: es un conjunto de alternativas diseñadas para casos de uso donde el modelo relacional presenta limitaciones prácticas.
Las diferencias principales respecto a SQL son tres:
- Sin esquema fijo: no hay tablas con columnas predefinidas. La estructura de los datos puede variar de un registro a otro.
- Escalado horizontal: están diseñadas para distribuirse en múltiples servidores, algo que las bases de datos relacionales tradicionales hacen con más dificultad.
- Consistencia eventual: algunas NoSQL priorizan la disponibilidad y la velocidad sobre la consistencia inmediata. Sacrifican parte de las garantías ACID a cambio de rendimiento.
Tipos de bases de datos NoSQL
Documentales
Almacenan los datos como documentos, generalmente en formato JSON o BSON. Cada documento es una unidad autocontenida que puede tener una estructura diferente. Son el tipo de NoSQL más usado. Ejemplos: MongoDB, CouchDB, Firestore.
Clave-valor
El modelo más simple: cada dato es un par clave → valor, como un diccionario gigante en memoria. Son extremadamente rápidas porque recuperar un valor solo requiere conocer su clave. Ejemplos: Redis, Memcached, DynamoDB.
Columnares
A diferencia de las bases de datos relacionales, que almacenan los datos fila a fila, estas los almacenan columna a columna. Son muy eficientes para consultas analíticas que suman o agregan columnas enteras sobre millones de filas. Ejemplos: Apache Cassandra, Amazon Redshift, ClickHouse.
Grafos
Modelan los datos como nodos (entidades) y aristas (relaciones). Son la herramienta natural cuando las relaciones entre datos son tan importantes como los datos en sí. Ejemplos: Neo4j, Amazon Neptune.
MongoDB en la práctica
MongoDB es la base de datos documental más extendida. Los datos se organizan en colecciones (equivalente a tablas) que contienen documentos (equivalente a filas). La diferencia es que cada documento puede tener una estructura diferente.

La ventaja es inmediata en catálogos de productos: un teclado tiene switches y retroiluminación; un monitor tiene resolución y frecuencia; un cable USB no tiene ninguno de esos campos. En SQL necesitarías columnas nulas o tablas separadas para cada tipo. En MongoDB cada documento tiene exactamente lo que necesita.
Las operaciones básicas en MongoDB usan una sintaxis orientada a objetos:
// Insertar un documento
db.productos.insertOne({
nombre: "Teclado mecánico",
precio: 89.99,
tags: ["gaming", "rgb"],
specs: { switches: "Cherry MX Red" },
stock: { madrid: 12, barcelona: 4 }
});
// Buscar un documento
db.productos.findOne({ nombre: "Teclado mecánico" });
// Buscar todos los productos por encima de cierto precio
db.productos.find({ precio: { $gt: 50 } });
// Actualizar un campo
db.productos.updateOne(
{ nombre: "Teclado mecánico" },
{ $set: { precio: 79.99 } }
);
// Eliminar
db.productos.deleteOne({ nombre: "Teclado mecánico" });Cuándo usar MongoDB: datos semiestructurados o con esquema variable, catálogos de contenido, aplicaciones donde el esquema evoluciona rápido durante el desarrollo, o cuando necesitas almacenar documentos JSON directamente sin transformarlos.
Redis en la práctica
Redis es una base de datos clave-valor que vive íntegramente en memoria RAM. Eso la hace entre cien y mil veces más rápida que cualquier base de datos en disco para lecturas y escrituras simples. Su uso más habitual es como capa de caché frente a una base de datos más lenta.
# Guardar un valor con tiempo de expiración (caché de 1 hora)
SET producto:1:precio "89.99" EX 3600
# Leer el valor
GET producto:1:precio
# Guardar datos de sesión de usuario
SET sesion:usuario:42 "{nombre: Ana, rol: admin}" EX 86400
# Contador de visitas (operación atómica)
INCR visitas:pagina:home
# Lista como cola de tareas (push izquierda, pop derecha)
LPUSH cola:emails "ana@ejemplo.com"
RPOP cola:emailsEl parámetro EX define el tiempo de vida en segundos (TTL). Cuando expira, Redis elimina la clave automáticamente. Eso es perfecto para caché: si el dato no está en Redis, la aplicación lo busca en la base de datos relacional y lo vuelve a guardar en Redis para la próxima petición.
Cuándo usar Redis: caché de consultas costosas, almacenamiento de sesiones de usuario, contadores en tiempo real, colas de mensajes simples, rankings y tablas de líderes, o cualquier dato que necesite acceso en microsegundos y tiene una vida útil limitada.
¿SQL o NoSQL?
La elección no es ideológica. Cada herramienta tiene un perfil de problema para el que está optimizada:
- Usa SQL cuando los datos tienen relaciones claras entre sí, necesitas garantías ACID para operaciones críticas (pagos, reservas, stock) o el esquema es estable y bien definido.
- Usa una base de datos documental cuando los datos tienen estructura variable, el esquema cambia frecuentemente o almacenas documentos JSON directamente.
- Usa clave-valor cuando la velocidad es crítica y el modelo de acceso es siempre por una clave única: caché, sesiones, configuración.
- Usa una columnar cuando procesas analítica sobre volúmenes enormes de datos históricos: suma de ventas, métricas agregadas, reporting.
- Usa una de grafos cuando las relaciones entre entidades son el núcleo del problema: redes sociales, sistemas de recomendación, detección de fraude.
En la práctica conviven
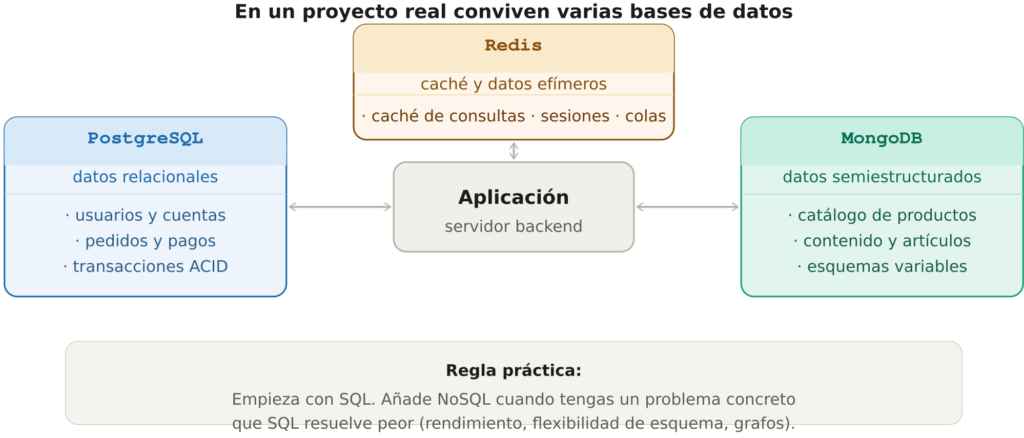
En proyectos reales no suele ser una decisión de uno u otro. Una arquitectura habitual combina PostgreSQL para los datos relacionales críticos (usuarios, pedidos, pagos), Redis como capa de caché para consultas frecuentes y gestión de sesiones, y MongoDB para el catálogo de productos o el contenido editorial donde el esquema varía.
La regla práctica es sencilla: empieza con SQL. Es más fácil de razonar, más predecible y tiene un ecosistema de herramientas más maduro. Añade NoSQL cuando encuentres un problema concreto y medido que SQL resuelve peor. No al revés.
Saber qué hay detrás de una base de datos —cómo se modela, cómo se consulta, cómo se protege la integridad y cuándo una arquitectura diferente encaja mejor— es lo que convierte el acceso a datos de algo mecánico en una decisión de diseño consciente.