Imagina una tabla donde guardas los pedidos de una tienda: el nombre del cliente, su email, los productos del pedido y el precio. Parece razonable. Pero cuando Ana cambia de email tienes que actualizarlo en cincuenta filas distintas. Y si borras el único pedido que contiene un producto concreto, pierdes su información para siempre. Eso no es un problema de código: es un problema de diseño.
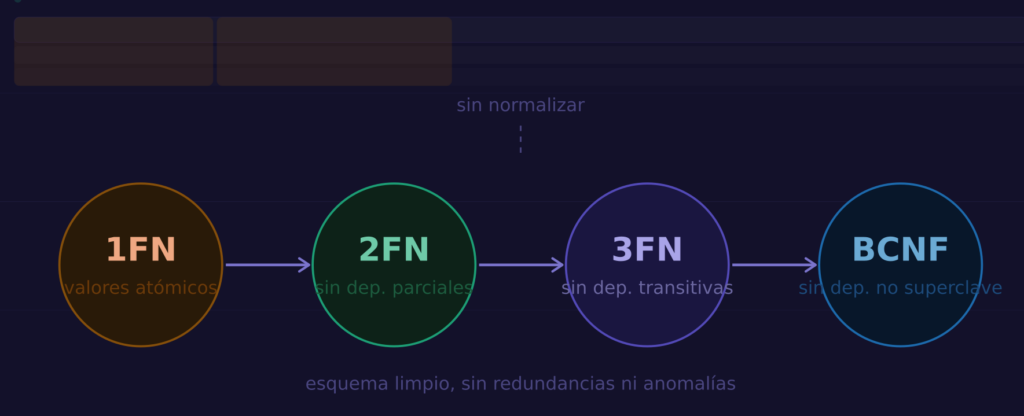
¿Qué es normalizar?
Normalizar es el proceso de organizar las columnas y las tablas de una base de datos para eliminar redundancias y garantizar que cada dato vive en un único lugar. El resultado es un modelo más limpio, más fácil de mantener y menos propenso a inconsistencias.
La teoría de la normalización define una serie de formas normales: niveles progresivos de organización, cada uno construido sobre el anterior. En la práctica, llegar a la tercera forma normal (3FN) es suficiente para la gran mayoría de aplicaciones.
La tabla de partida
Usaremos esta tabla como ejemplo a lo largo del artículo:
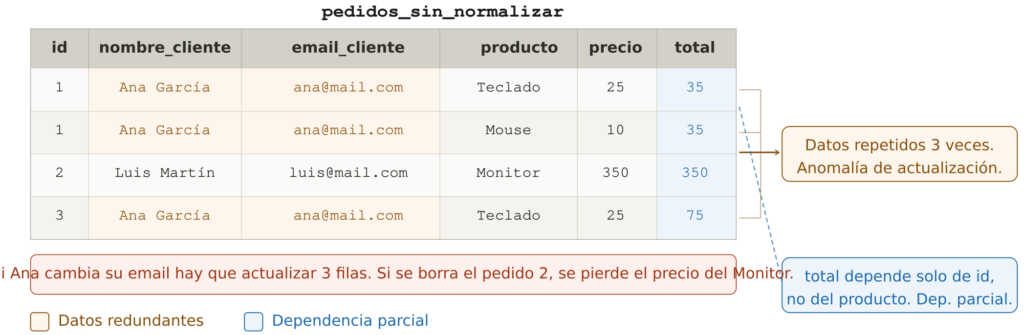
Los problemas son evidentes:
- El nombre y el email de Ana aparecen en tres filas distintas. Si cambia de email, hay que actualizar tres registros (anomalía de actualización).
- La columna
totaldepende solo delid_pedido, no de qué producto esté en la fila (dependencia parcial). - Si eliminamos el pedido 2, perdemos la información sobre el precio del Monitor (anomalía de borrado).
Primera Forma Normal (1FN)
Una tabla está en primera forma normal cuando cada celda contiene un único valor atómico: no puede haber listas, conjuntos ni valores múltiples en una misma columna.
Un error habitual al diseñar la primera versión de una tabla es guardar varios valores en un campo:
-- Mal: varios productos en un solo campo
id_pedido | productos
1 | 'Teclado, Mouse'
2 | 'Monitor'-- Bien: una fila por cada producto (1FN)
id_pedido | producto
1 | 'Teclado'
1 | 'Mouse'
2 | 'Monitor'Nuestra tabla de ejemplo ya cumple 1FN: cada celda tiene un valor único. El problema no está en los valores, sino en cómo están distribuidos entre columnas.
Segunda Forma Normal (2FN)
Una tabla está en segunda forma normal cuando cumple 1FN y además todos sus atributos no clave dependen de la clave primaria completa, no de una parte de ella.
En nuestra tabla, si definimos la clave primaria como (id_pedido, producto):
nombre_clienteyemail_clientedependen solo deid_pedido(dependencia parcial).preciodepende solo deproducto(dependencia parcial).totaldepende solo deid_pedido(dependencia parcial).
La solución es separar los datos según de qué parte de la clave dependen:
-- Tabla de clientes: datos que dependen del cliente
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(100),
email VARCHAR(100)
);
-- Tabla de pedidos: datos que dependen del pedido
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT REFERENCES clientes(id_cliente),
total DECIMAL(10,2)
);
-- Tabla de productos: datos que dependen del producto
CREATE TABLE productos (
id_producto INT PRIMARY KEY,
nombre VARCHAR(100),
precio DECIMAL(10,2)
);Tercera Forma Normal (3FN)
Una tabla está en tercera forma normal cuando cumple 2FN y además no hay ninguna columna no clave que dependa de otra columna no clave. Esto se llama dependencia transitiva.
Un ejemplo clásico: si a la tabla clientes añades una columna ciudad y otra pais, la columna pais no depende directamente del cliente, sino de la ciudad. Hay una cadena transitiva: id_cliente → ciudad → pais.
-- Viola 3FN: pais depende de ciudad, no de id_cliente
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(100),
ciudad VARCHAR(100),
pais VARCHAR(100) -- depende de ciudad, no de id_cliente
);
-- Correcto: separar la relación ciudad-país
CREATE TABLE paises (
id_pais INT PRIMARY KEY,
nombre VARCHAR(100)
);
CREATE TABLE ciudades (
id_ciudad INT PRIMARY KEY,
nombre VARCHAR(100),
id_pais INT REFERENCES paises(id_pais)
);
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(100),
id_ciudad INT REFERENCES ciudades(id_ciudad)
);El esquema final
Aplicando 1FN, 2FN y 3FN, la tabla original se transforma en cuatro tablas limpias, sin redundancias y con relaciones explícitas:
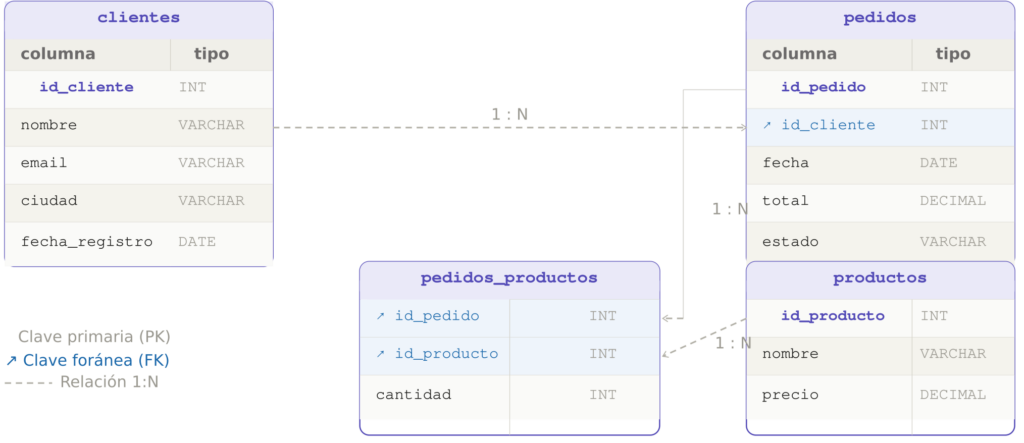
Cada dato vive ahora en un único lugar. Si Ana cambia de email, se actualiza en una sola fila de clientes y el cambio se propaga automáticamente a todos sus pedidos. Si se elimina un pedido, la información del producto permanece intacta en su propia tabla.
Forma Normal de Boyce-Codd (BCNF)
BCNF es una versión más estricta de la 3FN. La regla es: para cada dependencia funcional X → Y en la tabla, X debe ser una superclave. La 3FN tiene una pequeña excepción que permite dependencias donde Y forma parte de alguna clave candidata. BCNF elimina esa excepción sin excepciones.
En la práctica, la diferencia solo aparece cuando una tabla tiene varias claves candidatas que se superponen. Considera esta tabla de asignaciones de almacén:
-- cobertura_almacen
-- id_producto | almacen | encargado
-- 1 | Madrid | García
-- 2 | Madrid | García
-- 3 | Barcelona | LópezLas dependencias funcionales son:
(id_producto, almacen) → encargado: cada producto en un almacén tiene un único encargado.encargado → almacen: cada encargado trabaja en un único almacén.
Existen dos claves candidatas: (id_producto, almacen) y (id_producto, encargado). La tabla cumple 3FN porque almacen sí forma parte de una clave candidata. Sin embargo, viola BCNF: la dependencia encargado → almacen existe, pero encargado solo no es una superclave.
El problema concreto: si García se traslada de Madrid a Valencia, hay que actualizar múltiples filas. La solución es descomponer en dos tablas donde cada dependencia tenga su superclave:
-- Tabla 1: dónde trabaja cada encargado
CREATE TABLE encargados_almacen (
encargado VARCHAR(100) PRIMARY KEY,
almacen VARCHAR(100) NOT NULL
);
-- Tabla 2: qué productos gestiona cada encargado
CREATE TABLE cobertura (
id_producto INT,
encargado VARCHAR(100) REFERENCES encargados_almacen(encargado),
PRIMARY KEY (id_producto, encargado)
);Ahora encargado → almacen queda capturada en su propia tabla con la superclave correcta y el problema de actualización desaparece.
En el diseño habitual de aplicaciones este caso es infrecuente: la mayoría de tablas en 3FN están automáticamente en BCNF. La distinción importa cuando el modelo incluye restricciones complejas con múltiples claves candidatas superpuestas, algo más frecuente en sistemas de gestión académica, horarios o asignación de recursos.
¿Cuándo desnormalizar?
La normalización es la norma, pero no siempre la regla absoluta. En sistemas con volúmenes muy altos de lecturas (como analítica o reporting), un JOIN entre cuatro tablas puede ser más lento que mantener algunos datos duplicados deliberadamente. Esto se llama desnormalización controlada.
La clave es que la desnormalización sea una decisión consciente basada en métricas de rendimiento, no el resultado de no haber diseñado bien desde el principio. Primero normaliza. Desnormaliza solo cuando tengas un problema real medido.
Con un esquema bien normalizado, SQL, índices y transacciones, tienes todo lo necesario para trabajar con bases de datos relacionales en la inmensa mayoría de proyectos. Pero las bases de datos relacionales no son la única herramienta disponible. Hay problemas concretos donde otra arquitectura encaja mejor.