Tienes una tabla con un millón de clientes y ejecutas WHERE email = 'ana@ejemplo.com'. Sin ninguna ayuda adicional, la base de datos lee el millón de filas una a una hasta encontrar la que coincide. Eso se llama full table scan, y es exactamente el tipo de problema que resuelven los índices.
¿Qué es un índice?
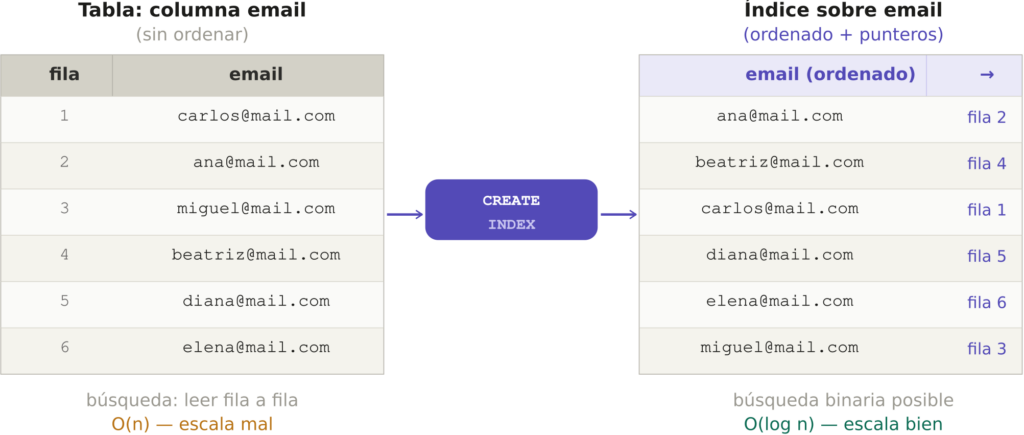
Un índice es una estructura de datos separada que la base de datos mantiene junto a la tabla. Almacena una copia ordenada de una o varias columnas y, junto a cada valor, guarda un puntero a la fila original. Cuando ejecutas una consulta con una condición sobre esa columna, la base de datos consulta primero el índice en lugar de leer la tabla entera.

La diferencia de rendimiento se vuelve enorme a medida que la tabla crece. Una tabla con diez filas no nota nada. Una tabla con diez millones de filas puede pasar de segundos a milisegundos.
Cómo funciona internamente: el árbol B
La mayoría de bases de datos relacionales implementan los índices como un árbol B (B-tree, del inglés balanced tree). Es una estructura jerárquica de nodos que mantiene los valores ordenados y equilibrada en altura. Cada consulta recorre el árbol desde la raíz hasta una hoja siguiendo comparaciones, y el número de comparaciones necesarias es el logaritmo del tamaño del índice.
En la práctica: para encontrar un valor entre un millón de registros, un árbol B necesita como máximo veinte comparaciones. Sin índice, el peor caso son un millón de lecturas.
El índice no modifica los datos de la tabla. Es una estructura auxiliar que la base de datos actualiza automáticamente cuando insertas, modificas o eliminas filas.
Crear un índice
La instrucción es CREATE INDEX:
CREATE INDEX idx_usuarios_email ON usuarios(email);La convención habitual para el nombre es idx_ seguido del nombre de la tabla y la columna. No es obligatorio, pero ayuda a identificar el índice más adelante.
Para eliminar un índice:
-- MySQL
DROP INDEX idx_usuarios_email ON usuarios;
-- PostgreSQL
DROP INDEX idx_usuarios_email;Tipos de índices
Índice simple
El caso básico: un índice sobre una sola columna. Acelera las consultas que filtran, ordenan o hacen JOIN por esa columna.
CREATE INDEX idx_pedidos_fecha ON pedidos(fecha);Índice único
UNIQUE crea el índice y además impone la restricción de que no puede haber dos filas con el mismo valor en esa columna. Es la forma correcta de garantizar que un campo como el email no se repita.
CREATE UNIQUE INDEX idx_usuarios_email ON usuarios(email);Índice compuesto
Un índice sobre varias columnas a la vez. Es útil cuando tus consultas filtran por una combinación de campos de forma habitual.
CREATE INDEX idx_pedidos_usuario_fecha ON pedidos(id_usuario, fecha);Un índice compuesto sobre (id_usuario, fecha) acelera consultas que filtran por id_usuario solo o por id_usuario y fecha juntos. No acelera consultas que filtran únicamente por fecha. El orden de las columnas importa.
La clave primaria ya está indexada
Todas las bases de datos relacionales crean automáticamente un índice sobre la clave primaria. Por eso las búsquedas por id son siempre rápidas sin que tengas que hacer nada. Las restricciones UNIQUE también generan su índice de forma automática.
Cuándo crear un índice
Un índice tiene un coste: ocupa espacio en disco y ralentiza ligeramente las escrituras (INSERT, UPDATE, DELETE), porque la base de datos tiene que mantener la estructura actualizada. No es gratuito.
Crea un índice cuando:
- La columna aparece con frecuencia en cláusulas
WHERE,JOIN ONuORDER BY. - La tabla tiene un volumen considerable de filas (miles o más).
- La columna tiene alta cardinalidad, es decir, muchos valores distintos. Un índice sobre una columna con solo dos valores posibles (activo/inactivo) apenas mejora nada.
No crees un índice cuando:
- La tabla es pequeña: el full scan será igual de rápido o más.
- La columna rara vez se usa en filtros o JOINs.
- La tabla recibe un volumen altísimo de escrituras y cada milisegundo cuenta: los índices añaden coste a cada operación de escritura.
EXPLAIN: comprueba si el índice se usa
Crear un índice no garantiza que la base de datos lo use. El optimizador de consultas decide si un índice conviene o no en cada caso. Para ver qué hace realmente, usa EXPLAIN antes de la consulta:
EXPLAIN SELECT * FROM usuarios WHERE email = 'ana@ejemplo.com';La salida varía según el gestor, pero los campos clave son siempre los mismos:
- type (MySQL) o Seq Scan / Index Scan (PostgreSQL): indica si se hace un scan completo o se usa el índice.
- key (MySQL): muestra qué índice se está usando. Si está vacío, no se usa ninguno.
- rows: estimación del número de filas que se van a examinar. Cuanto menor, mejor.
-- PostgreSQL: versión detallada con tiempos reales
EXPLAIN ANALYZE SELECT * FROM usuarios WHERE email = 'ana@ejemplo.com';EXPLAIN ANALYZE ejecuta la consulta realmente y muestra los tiempos reales junto a la estimación. Es la herramienta más directa para detectar consultas lentas y confirmar si un índice está teniendo efecto.
Los índices garantizan que tus consultas sean rápidas. Pero velocidad sin integridad no es suficiente. ¿Qué ocurre si una operación falla a mitad de camino y los datos quedan en un estado inconsistente? Ahí es donde entran las transacciones.