Cada vez que tu navegador carga una página, envía un formulario o descarga una imagen, está usando HTTP. Es el protocolo que hace posible la web tal como la conocemos. Sin entenderlo, puedes escribir código backend que funcione, pero no entenderás por qué funciona ni cómo depurarlo cuando falle.
¿Qué es HTTP?
HTTP son las siglas de HyperText Transfer Protocol: el protocolo que define cómo se comunican el cliente y el servidor en la web. Un protocolo es, simplemente, un conjunto de reglas acordadas. HTTP establece cómo debe formularse una petición y cómo debe estructurarse la respuesta.
La versión actual más extendida es HTTP/1.1, aunque HTTP/2 y HTTP/3 están ganando terreno por su mayor velocidad. El mecanismo fundamental, sin embargo, es el mismo en todas las versiones: el cliente hace una petición, el servidor devuelve una respuesta.
Una cosa importante: HTTP es un protocolo sin estado (stateless). Cada petición es independiente. El servidor no recuerda que ya hablaste con él hace dos segundos. Esto tiene implicaciones directas en cómo se gestiona la autenticación, tema que veremos en el artículo 4.
Anatomía de una petición HTTP
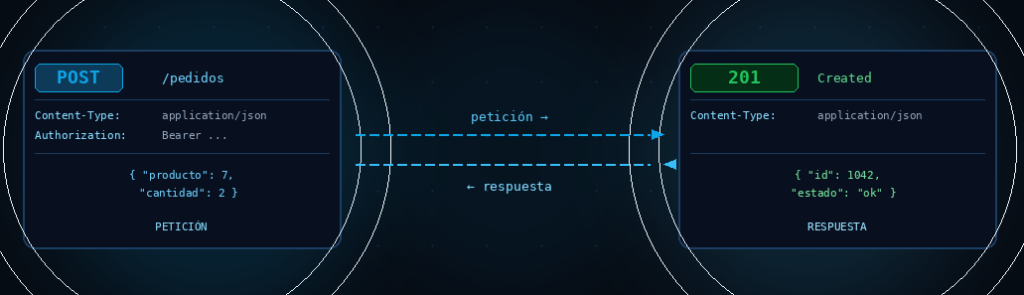
Cuando tu navegador visita https://api.ejemplo.com/usuarios/42, envía algo parecido a esto:
GET /usuarios/42 HTTP/1.1
Host: api.ejemplo.com
Accept: application/json
Authorization: Bearer eyJhbGci...
Una petición HTTP tiene tres partes:
- Línea de inicio: El método (
GET), la ruta (/usuarios/42) y la versión del protocolo. - Cabeceras: Metadatos sobre la petición. Quién hace la petición, qué formato acepta, si va autenticada.
- Cuerpo: Los datos que se envían. Solo existe en peticiones que mandan información al servidor (POST, PUT, PATCH). En un GET no hay cuerpo.
Los métodos HTTP
El método indica qué quiere hacer el cliente con el recurso. Hay varios, pero cuatro son los que usarás el 95% del tiempo:
- GET: Obtener un recurso. No modifica nada en el servidor. Pides un usuario, una lista de productos, un artículo. Nunca uses GET para operaciones que cambien datos.
- POST: Crear un recurso nuevo. Envías datos en el cuerpo de la petición. Registrar un usuario, publicar un comentario, crear un pedido.
- PUT: Reemplazar un recurso completo. Envías el recurso entero con todos sus campos, aunque solo hayas cambiado uno.
- PATCH: Modificar parcialmente un recurso. Solo envías los campos que quieres cambiar, no el recurso completo.
- DELETE: Eliminar un recurso. La respuesta habitual es un 204 sin cuerpo o un 200 con confirmación.
La diferencia entre PUT y PATCH es sutil pero importante. Si tienes un usuario con nombre, email y teléfono, y solo quieres cambiar el teléfono: con PUT envías los tres campos (si no mandas el nombre, se borra), con PATCH envías solo el teléfono.
Los códigos de estado
Cada respuesta HTTP incluye un código de tres dígitos que indica qué pasó. Están agrupados por centenas:
2xx — Éxito
- 200 OK: La petición se completó correctamente. Es la respuesta más habitual en un GET.
- 201 Created: Se creó un nuevo recurso. Respuesta correcta para un POST exitoso.
- 204 No Content: La petición se procesó correctamente pero no hay nada que devolver. Habitual en DELETE.
3xx — Redirecciones
- 301 Moved Permanently: El recurso se ha movido a otra URL de forma permanente. El cliente debe actualizar sus enlaces.
- 302 Found: Redirección temporal. El cliente debe seguir usando la URL original en el futuro.
4xx — Error del cliente
- 400 Bad Request: La petición está mal formada. Falta un campo obligatorio, el formato es incorrecto o los datos no pasan la validación.
- 401 Unauthorized: No estás autenticado. Necesitas identificarte antes de acceder a este recurso.
- 403 Forbidden: Estás autenticado, pero no tienes permisos para este recurso. La diferencia con 401 es importante: el servidor te conoce, pero no te deja pasar.
- 404 Not Found: El recurso no existe. Puede ser que nunca haya existido o que lo hayas borrado.
- 422 Unprocessable Entity: La petición está bien formada pero los datos no son válidos semánticamente. Por ejemplo, una fecha de nacimiento en el futuro.
- 429 Too Many Requests: Has superado el límite de peticiones. El servidor te pide que esperes antes de volver a intentarlo.
5xx — Error del servidor
- 500 Internal Server Error: Algo falló en el servidor. El error genérico que aparece cuando hay una excepción no controlada.
- 502 Bad Gateway: El servidor actuó como intermediario y recibió una respuesta inválida del servidor de destino.
- 503 Service Unavailable: El servidor no puede atender peticiones en este momento. Sobrecarga o mantenimiento.
Las cabeceras HTTP
Las cabeceras son pares clave-valor que añaden contexto a la petición o a la respuesta. Las más relevantes en backend:
- Content-Type: Indica el formato del cuerpo.
application/jsonpara JSON,multipart/form-datapara ficheros. Si mandas JSON pero no declaras este header, el servidor puede no saber cómo leerlo. - Authorization: Lleva las credenciales de autenticación. Habitualmente un token en formato
Bearer <token>. - Accept: Le dice al servidor en qué formato quiere recibir la respuesta. Si pones
application/json, estás pidiendo JSON. - Cache-Control: Controla si la respuesta puede almacenarse en caché y durante cuánto tiempo.
- CORS (Access-Control-Allow-Origin): Controla desde qué dominios se puede acceder a la API. Si alguna vez has visto el error «CORS policy» en el navegador, aquí está la causa.
HTTPS: HTTP con cifrado
HTTPS no es un protocolo diferente: es HTTP con una capa de cifrado por encima llamada TLS (Transport Layer Security). Todo lo que viaja entre cliente y servidor va cifrado, de forma que aunque alguien intercepte el tráfico, no pueda leerlo.
Hoy en día cualquier API o aplicación web debe usar HTTPS. Los navegadores marcan como inseguros los sitios que siguen en HTTP, y herramientas como Let’s Encrypt hacen que obtener un certificado TLS sea gratuito y automático.
¿Por qué no inventar tu propio protocolo?
Podrías diseñar tu propio sistema de comunicación entre cliente y servidor. El problema es que perderías todo el ecosistema construido alrededor de HTTP: navegadores, proxies, cachés, herramientas de depuración, librerías en todos los lenguajes, middlewares de seguridad. HTTP lleva décadas de evolución y optimización. Usarlo es aprovechar ese trabajo acumulado.